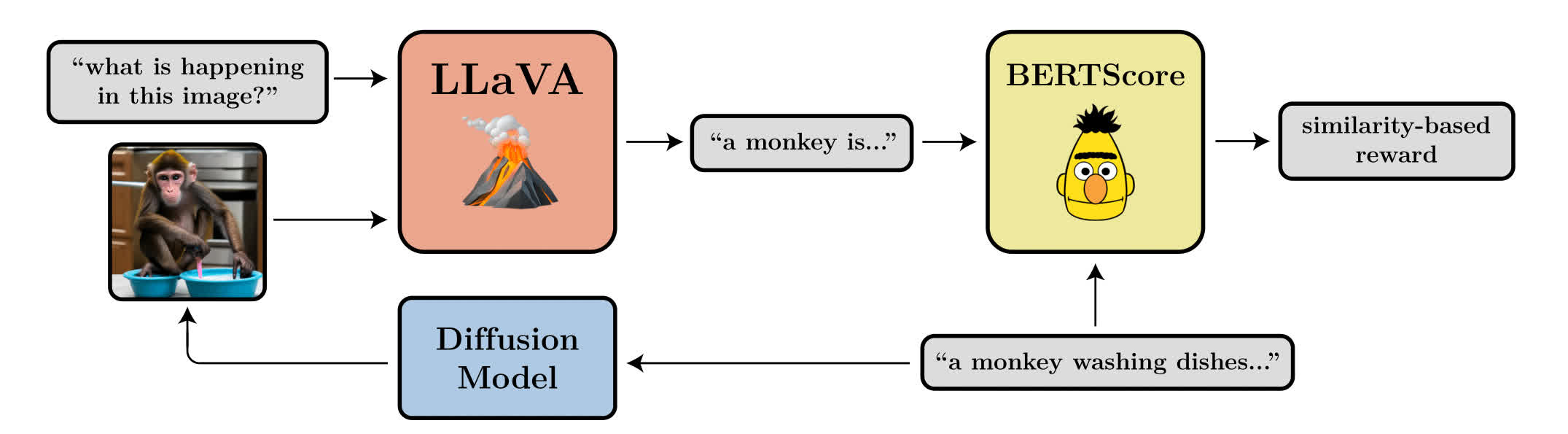
ㅎㅎ 6월을 건너뛰고 벌써 7월이라니.. Training Diffusion Models with Reinforcement Learning Diffusion model을 강화학습 관점에서 바라봄 reward-weighted likelihood 방식보다 효과적이라고 주장 Diffusion model은 likelihood를 maximize하도록 학습이 되는데, 실제로 디퓨전 모델 자체는 그런 용도로 쓰이지 않음. Diffusion model의 likelihood를 계산하는 것은 intractable -> 전체 denoising 과정에서의 likelihood 대신 denoising의 각 step에서의 정확한 likelihood를 이용 VLM 모델을 이용해서 사람의 feedback이 필요한 labeling을 대체..