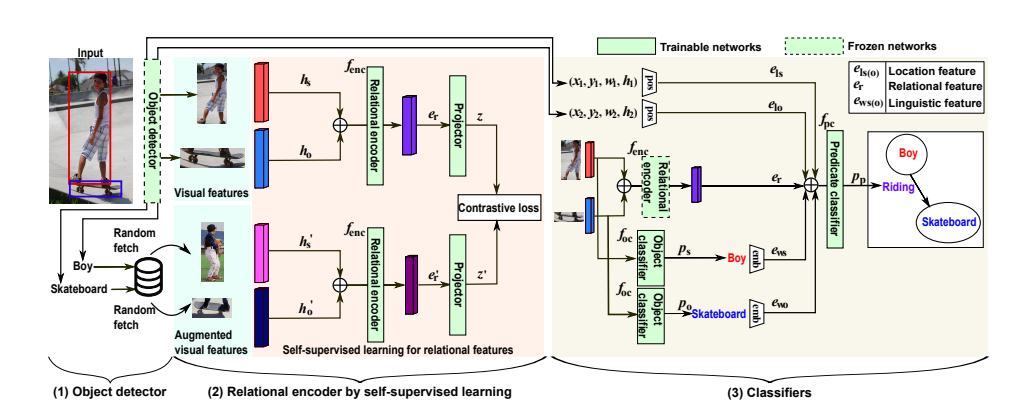
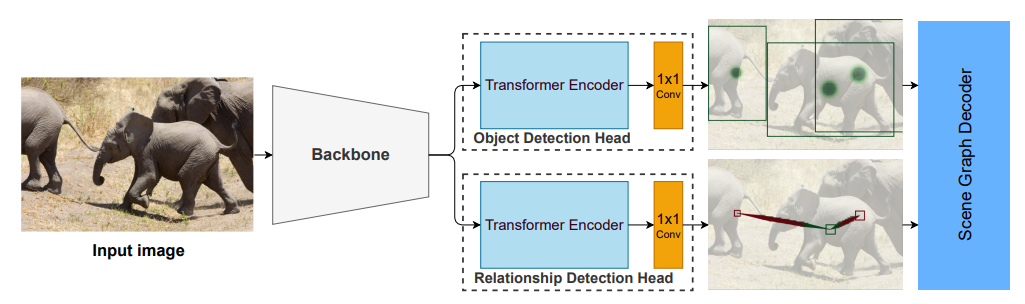
Abstract Vision-and-language pre-training은 대규모 모델을 end-to-end로 학습시키는 방식 때문에 점점 더 비용이 많이 들고 있다. 이 논문에서는 BLIP-2라는 새로운 pre-traning 전략을 제시한다. BLIP-2는 미리 학습된 이미지 인코더와 llm을 frozen 시킨 채로 vision-language pre-training을 bootstrap 하는 방식이다. BLIP-2는 lightweight Querying Transformer를 사용하여 vision과 language 사이의 gap을 연결하며, 이 transformer는 두 단계로 pre-train 된다. 먼저 frozen 이미지 인코더를 활용해 vision-language representation l..