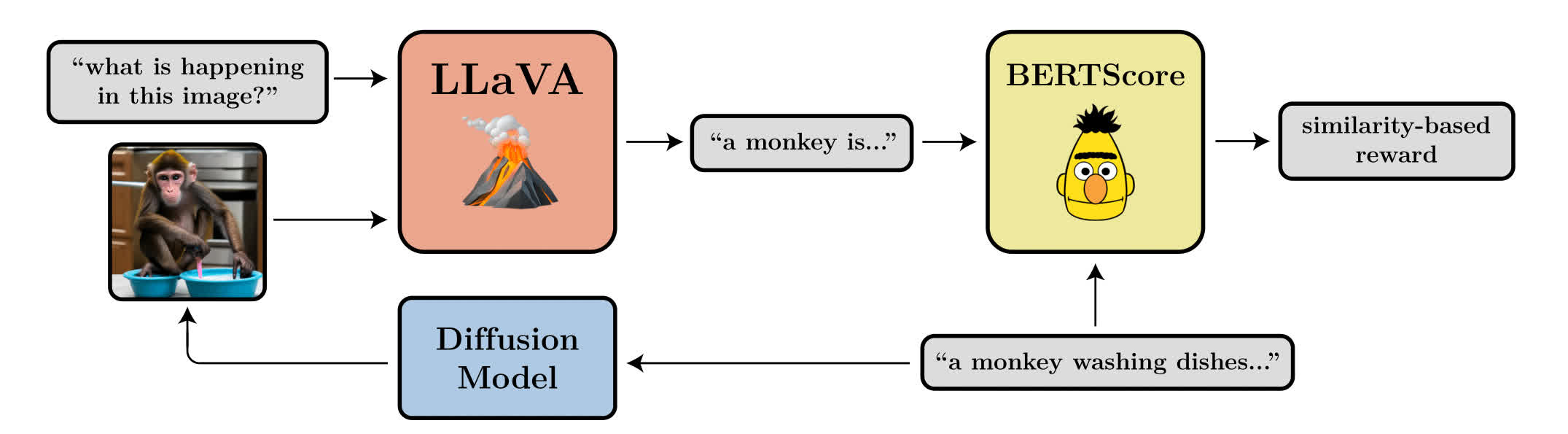
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation 적은 양의 이미지 (5장-6장) 를 가지고 모델을 파인튜닝해서 개인을 위한 Text-to-Image Diffusion Model을 만들 수 있다! 'sks'와 같은 vocab에 없을 것 같은 특이한 단어 (identifier)를 객체 앞에 넣어서 같이 학습한다. (위의 사진에서 "A [V] dog" 부분의 [V]가 결국 identifier 같은 느낌 Prior도 학습해서 원래 개의 특성도 학습하면서 [V] dog 이라는 특정 개만의 특성도 학습 FABRIC: Personalizing Diffusion Models with Iterative Feedback..