Using Language to Extend to Unseen Domains

- data augmentation 관련 논문
- 모든 domain에 대해서 데이터를 수집하는건 사실상 불가능하니까, [yellow]verbalizing[/yellow]
- task와 관련된 정보는 유지하되 training domain에서 각 unseen test domain으로 이미지 임베딩 (latent)을 변환하는 과정을 학습 (pixel이 아니라!) -> 이미지 자체를 직접 augmentation 하는게 아니라 latent space 상에서의 augmentation
- augmentation을 학습한 후, 단순한 linear classifier를 학습
- 데이터 augmentation 하고 fine-tuning하는 느낌
- unseen test domain을 보지는 않지만, unseen test domain에 존재하는 class이름이나 domain description은 사용
- LDA: clip을 사용해서 image 관점에서의 global direction과 text 관점에서 global direction을 구한 후, 이 둘이 같아지도록 학습 (여기에서 global direction은 training domain에서 unseen test domain 으로의 방향을 의미)
- fkaug는 unseen test domain k 에 대해 augmenation하는 모듈
- LCC: augmented embedding이 class정보를 잘 담고 있을 수 있도록 함 (CLIP loss와 동일 - 가능한 class name들과 augmented embedding 내적 구해서 원래 class name과의 내적 값이 가장 큰 값을 가질 수 있도록~)
General Incremental Learning with Domain-aware Categorical Representations
- stability-plasticity dilemma를 계속 언급하는데 아마, 기존의 정보를 잊지 않는 것과 새로운 정보를 학습하는 것 사이의 trade off를 말하는 듯
- 각 class 마다, 도메인에 대한 clustering을 하는 느낌
- 일단 잘게 cluster 개수가 많도록 clustering을 하고(Expansion) 모델을 학습한 후 다시 cluster 개수를 줄이는(Reduction) 느낌
- 학습은 EM framework를 이용해서 학습하며 E-Step, M-Step으로 구성되어 있음
- E-Step: 마지막 M-step에서 학습된 파라미터 (이전 세션의 모델)을 가지고 new estimate of the component assignments를 계산. 즉, 이미지와 class가 주어졌을 때 해당 데이터의 도메인 클러스터를 ˆz로 할당하는 느낌 (Eq. 6). normalized image feature와 가장 가까운 클러스터 중심을 가지고 있는 클러스터로 할당 하는 듯.
- M-Step: E-step에서 얻은 할당된 클러스터를 가지고 loss를 계산해서 모델을 업데이트
- Lcls: E-step에서 얻은 할당된 클러스터를 이용함. 이미지가 주어졌을 때 mixture model이 클래스를 잘 예측할 수 있도록 + 이미지와 클래스가 주어졌을 때 E-step에서 얻은 ˆz을 예측하도록 구성되어 있는 듯 (Eq.8~9)
- Ldis: 정보를 잘 유지할 수 있도록 knowledge distillation, 모델이 크게 바뀌는 것 방지
- Lreg: Mixture model에 대해서 reugalrization => domain을 over-segmentation 하는 것 방지
Adding Conditional Controols to Text-to-Image Diffusion Model
- 추가적인 condition을 이용해서 pretrained model을 [yellow]control[/yellow]
- task-specific condition을 학습함.
- trainable copy와 zero convolution
- 모델이 있으면 원래 모델의 파라미터를 fix하고, trainable copy에 모델의 파라미터를 복사함
- ControlNet을 추가한 Stable Diffusion을 보면 원래 모델인 stable diffusion의 파라미터는 고정되고, stable diffusion의 encoder와 middle block만 trainable copy에 추가되어 있어서, 거의 stable diffusion의 절반만 업데이트 -> 학습 빠름
ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation
- 처음으로 text-to-image human preference reward model을 제시한 논문
- 많은 생성모델들이 있지만, 사람의 선호와 잘 align 되는 것이 어려움
- 논문에서 DiffusionDB에서 prompt와 model output을 선택함. (각 prompt마다 4~9개의 image)
- 이 때, 선택된 prompt가 다양하고, 주제에 대해서 잘 표현할 수 있기를 원해서 graph-based selecting alogrithm을 통해서 prompt를 선택함
- 일단 prompt들을 가지고 유사도 그래프를 만드는데 각 노드가 prompt가 되고 각 노드의 이웃노드는 cosine similarity 기준으로 가장 가까운 k개의 노드가 됨.
- 그 다음 반복적으로 degree가 가장 높은 애를 선택함. 근데 어떤 노드가 선택되면 선택된 노드의 이웃 노드들의 degree를 내림. (각 노드는 선택되지 않은 이웃노드의 개수를 점수로 가지고 있음)

- 위의 그림과 같이 3가지 항목에 대해 1~7점을 받고, 주어진 이미지들의 순위를 매김
- 위의 과정을 통해서 데이터셋을 구축했으면 구축한 데이터를 가지고 Reward Model을 학습함.
- prompt와 그에 해당하는 ranked image를 input으로 받고, scalar value를 뱉는 preference model fθ(T,x) 존재 (T는 prompt, x는 생성된 이미지)
- 학습 로스는 아래와 같음
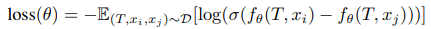
- 데이터셋 및 학습한 Reward Model (ImageReward)에 대한 여러 분석 결과를 제공
[1] Dunlap, Lisa, et al. "Using Language to Extend to Unseen Domains." arXiv preprint arXiv:2210.09520 (2022).
[2] Xie, Jiangwei, Shipeng Yan, and Xuming He. "General incremental learning with domain-aware categorical representations." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[3] Zhang, Lvmin, and Maneesh Agrawala. "Adding conditional control to text-to-image diffusion models." arXiv preprint arXiv:2302.05543 (2023).
[4] Xu, Jiazheng, et al. "ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation." arXiv preprint arXiv:2304.05977 (2023).