어쩌다 보니 WACV 2023 연속으로 2편 정리를 하게 됐당.. 그것도 SGG 논문..
컨셉
일반적으로 SGG에서 사용하는 데이터셋 (Visual Genome, Open Image 등) 은 매우 imbalnce하다. 따라서 데이터셋 내에서 자주 등장하는 class (head에 속하는 class) 를 위주로 학습하다보니, 데이터셋 내에서 등장하는 빈도가 적은 predicate class (tail에 속하는 class)는 잘 예측하지 못 한다. 하지만, 보통 head에 속하는 것들 (ex, on) 은 정보가 많이 없고 tail에 속하는 것들 (ex, standing on) 이 상대적으로 더 많은 정보를 가지고 있다. 이를 해결하기 위해서 많은 기법들이 등장했지만 대부분 tail에 속하는 class에 집중하도록 하여 모델이 tail class에 overfitting되고, 원래 잘 하던 head class에 대해서는 오히려 성능이 떨어지는 문제가 발생한다.
tail class에 대한 충분한 labeled data가 없기 때문에 이런 현상이 발생하므로 본 논문에서는 self-supervised 방식을 활용한다.
Proposed Method
Training Flow of SePiR
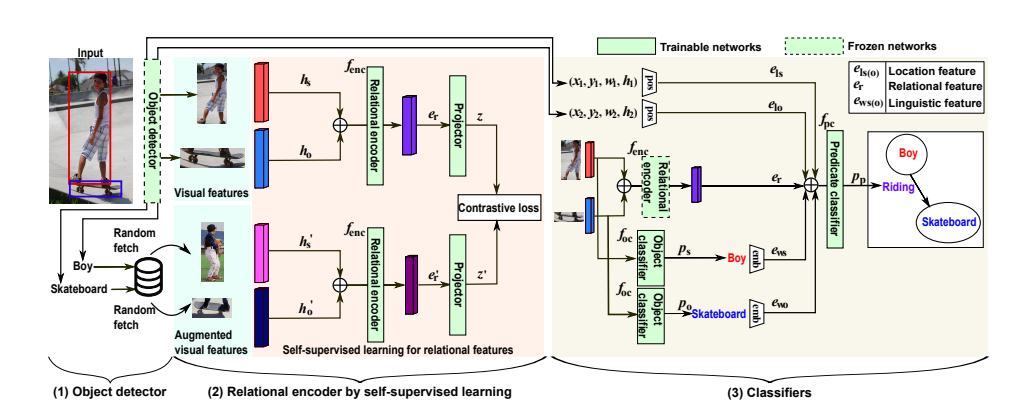
모델은 크게 3가지 step으로 이루어진다: 1) object detector 학습 2) relational encoder 학습 3) classifier 학습
일단 object detector는 DETR을 사용하고, object detector를 통해 object candidate를 생성하며 각 candidate는 visual feature $H$, tentative object labels $V_t$, bounding box $B$, $V_t$의 confidence score $C$를 가지고 있다.
그 다음 relational encoder는 self-supervised learning으로 학습되기 때문에 이 단계에서는 ground truth 라벨을 이용하지 않는다. relational encoder를 통해서 subject와 object의 visual feature $h_s, h_o$를 이용하여 relational feature $e_r$를 얻는다.
마지막으로 classifier를 학습한다. $h_s, h_o$를 가지고 subject, object classifier와 softmax 함수를 통해 각각 어떤 class인지 분류한다. predicate은 $e_r$과 각 subject, object에 해당하는 bounding box의 좌표 정보를 이용해 만든 location feature $e_{ls}, e_{lo}$ 그리고 각 subject, object에 해당하는 라벨의 GloVe embedding 결과인 $e_{ws}, e_{wo}$를 모두 이용하여 예측한다. 역시나 predicate classifier와 softmax를 통해 학습한다. (물체의 class를 예측하는 경우는 focal loss를, predicate class를 예측하는 경우는 일반적인 cross-entropy loss를 이용한다.)
3가지 모듈을 순차적으로 학습하는데, 한 번에 한 모듈만 학습한다. 즉, object detector를 학습한 후 relational encoder를 학습하는데 relational encoder를 학습할 때 object detector는 frozen 되어 있는 상태이다.
Self-Supervised Learning for Relational Features
1. How to truncate subject-object pairs

Object detector를 통해서 N개의 object proposal을 얻은 후, 겹치는 박스들을 합쳐준다. DETR의 경우 쿼리 갯수 만큼의 오브젝트를 뽑아내고 NMS와 같은 후처리 작업이 없기 때문에 중복되는 박스가 많기 때문에 박스 merge를 통해 중복을 줄여준다. (위의 그림 참조)
그 다음 pair confidence $c_{pair}$라는 것을 이용해서 한 번 더 걸러주는데, pair confidence는 subject, object class의 confidence score의 곱을 의미한다. $c_{pair} > c_{th}$ 인 경우 즉, pair confidence가 특정 값보다 큰 pair만 고려한다.

Object detector를 통해 N개의 오브젝트를 뽑아내면, N x (N-1)개의 pair가 존재하는데 pair의 갯수를 줄이는 과정이라고 보면 된다.
2. Details of the self-supervised learning
relational encoder를 학습할 때 ground truth label을 이용하지 않고 self-supervised 방식으로 학습한다. 보통 self-supervised 방식은 geometric, color transformation 등으로 data augmentation을 한다. 하지만, SGG task에서 predicate은 이미지 안에 명시적으로 드러나는게 아니라서 그런 augmentation을 predicate에는 적용할 수 없다. 그래서 본 논문에서 새로운 augmentation을 제안한다. 첫 번째 그림의 (b) 참조
- 원래 이미지 안에서 존재하는 subject와 object와 동일한 label을 가지는 subject와 object가 있는 이미지 $I_s^\prime, I_o^\prime$를 뽑는다.
- ($I_s^\prime, I_o^\prime$ 각각에서 그에 해당하는 visual feature $h_s^\prime, h_o^\prime$을 뽑아낸다.
- 원래 original visual feature를 $h_s^\prime, h_o^\prime$로 교체한다.
위의 과정을 통해 augmentation을 진행하면 original feature set ($h_s, h_o)$와 augmented set ($h_s^\prime, h_o^\prime)$이 존재하는데 2가지 set을 모두 relational encoder로 보내서 $e_r, e_r^\prime$을 생성한다. 그 후, projector를 통해서 $z, z^\prime$ 생성한다. SimCLR에서 사용한 contrastive loss function을 이용해서 original과 augmented pair의 relational feature가 서로 비슷해지도록, original과 negative pairs는 멀어지게 학습한다. (본 논문에서 negative pairs가 뭔지 정확하게 말해주지 않았지만, 아마 같은 배치 내에 다른 pair를 의미하는 것 같다.)
Experiments

tail class를 잘 예측하도록 했기 대문에 mR 성능이 매우 좋음


단순한 구조를 사용하기 때문에 파라미터 수도 다른 모델에 비해 매우 적고, inference time도 짧다. SGG는 다른 하위 task를 위해서 많이 사용되는데 inference time이 짧다는 것은 매우 큰 장점 같다.
참고 자료
- Hasegawa, So, et al. "Improving Predicate Representation in Scene Graph Generation by Self-Supervised Learning." Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2023.