S-Prompts Learning with Pre-trained Transformers: An Occam’s Razor for Domain Incremental Learning

- exemplar-free domain incremental learning
- 컨셉 자체는 엄청 확실하고 단순한 듯 함
- 보통 대부분의 continual learning은 catastrophic forgetting을 방지 하기 위해서 exemplar를 두고 이전 세션의 정보를 저장해둬서 활용함. 또는 prompt를 사용한 다른 방법들은 계속해서 prompt들을 sharing하고 있음 => 결국 이건 tug-of-war 즉, zero-sum 게임이라고 함. 새로운 정보를 같은 feature space상에 계속해서 쌓으니까 이게 섞이고 결국 좋은 성능을 내기 힘들다!
- exemplar 두는 것을 보안이나 개인정보 문제로 꺼리는 경우도 있음
- 일단 여기는 매 세션마다 도메인이 바뀌지만 이미지와 라벨이 같이 input으로 들어옴.
- Image S-Prompts와 Language-Image S-Prompts를 제시
- Image S-Prompts의 백본은 ViT이고, Language-Image S-Prompts의 백본은 CLIP
- 백본은 모두 고정하고, prompt와 classifier를 학습 함.
- (2가지 S-Prompts 모두 해당) Image Transfomer의 input은 x=[ximg,Pis,xcls] 이며 각각 이미지 토큰, image prompt, pre-trained class. Pis는 각 도메인마다 하나가 존재!
- (Language-Image S-Prompts의 경우) Text Transformer의 input은 tj=Pls,cj인데, 각각 text prompt, j번째 class name의 word embedding.
- Image S-Prompt는 각 도메인마다 하나의 linear classifier를 가지고 있으며 Language-Image S-Prompts는 CLIP처럼 contrastive loss를 통해 class 예측.
- inference할 때는 이 이미지가 어떤 도메인에 속하는지를 알아야 하니까, 저장된 도메인 centroid 중 input 이미지와 가장 가까운 centroid를 가진 도메인이라고 가정하고 prompt pool에서 해당하는 prompt를 가져옴
Lifelong Domain Adaptation via Consolidated Internal Distribution
- [yellow]consolidating the distribution[/yellow]을 통해서 DA 잡고, experience replay를 통해서 catastrophic forgetting을 잡음
- experience replay를 위해서, 각 class마다 mean에 가장 가까운 Mb=Nb/k 개를 버퍼에 저장하고 학습할 때 같이 사용 (Nb는 버퍼 사이즈, k는 class 개수)
- 처음에 initial source domain에 대해서 학습하면, 인코더는 input source distribution을 embedding space의 multi-modal distribution pJ(z)으로 매핑함. 이 때 각 mode는 각 class에 해당 (위의 그림에서 가운데 그림을 보면, 같은 클래스에 속하는 data는 같은 cluster에 매핑됨)
- GMM (Gaussian Mixture Model) p0J(z) 이용하는데, 이 때 각 cluster의 평균과 공분산을 알아야 함. (0의 의미는 첫 세션 즉, source domain 의미)
- 아래 수식을 통해서 GMM의 파라미터인 각 cluster의 평균과 공분산을 추정할 수 있음 (S0j은 j class에 속하는 데이터들)
- source domain이 아닌 경우(t가 0이 아닌 경우)는 unlabeled data가 들어오니까 pseudo-label dataset을 만들어서 사용
- 모델의 예측 confidence score가 threshold 값보다 큰 애들만 pseudo dataset에 포함 시킴.
- 아래 수식을 만족 시키는 파라미터 v,w를 찾아야 함. (각각 encoder, classifier의 파라미터)
- 첫번째 항은 pseudo-dataset에 대해서 잘 분류하도록, 두번째 항은 embedding space에 존재하는 분포와 target domain 분포를 잘 align하도록 (D는 probability discrepancy measure)
- 위에서 언급했듯이 replay를 통해서 catastrophic forgetting을 방지하는데, replay까지 추가하면 위의 수식이 아래와 같이 확장됨
- 위의 수식에서 두번째 항을 통해서 catastrophic forgetting을 방지하고, 네번째 항을 통해서 이전 세션의 모든 도메인들을 고려해서 분포를 합칠 수 있음.
T2I-Adapter: Learning Adapters to Dig out More Controllable Ability for Text-to-Image Diffusion Models
- 생성모델들의 성능이 매우 좋지만 원하는 이미지가 생성되지 않는 경우가 있음. 이는 생성 모델의 능력부족이 아니라 text가 생성 모델에게 충분히 정확한 guidance를 주고 있지 않기 때문
- 즉, 문제는 internal knowledge와 외부의 control signal 사이의 alignment issue
- T2I-adapter를 통해서 condition feature Ci를 생성해서 활용함.
- T2I-adapter는 4개의 feature extraction block과 3개의 downsample block 존재
- Fc={F1c,F2c,F3c,F4c}를 만드는데 얘네의 feature dimension은 U-Net Denoiser의 encoder 차원과 동일! (더할 수 있도록)
- 혹시 여러 condition을 합치고 싶다면, T2I-adapter 여러개를 합쳐서 multi-condition control을 하고 싶다면 T2I-adapter로 얻은 condition feature들을 weigthed sum 해주면 됨
- 학습할 때는 기본 SD와 비슷하게 학습함. (SD 모델의 파라미터는 fix하고 adapter만 학습)
- 학습 데이터는 original image, condition map, text prompt 이렇게 triplet으로 존재
- original image X0가 주어지면 encoder를 통해서 Z0을 생성하고, 하나의 time step을 랜덤하게 선택해서 Zt를 생성
- SD에서 time embedding이 매우 중요하고, 실제로 adapter한테도 time embedding을 해주는게 효과가 좋았지만 이러면 매 iteration에 참여해야해서 "simple"이 아님!
- 본 논문에서 main content는 앞에서 결정된다고 하는데 따라서 뒷 단계에 condition을 넣으면 무시됨. 따라서 T2I-adapter를 이용해서 생성한 condition feature를 앞쪽에 넣어주려고 함!
- 그래서 t를 unfirom sampling을 통해서 뽑지 않고, cubic function을 t의 분포로 활용함. (앞쪽에서 뽑을 수 있도록?)
- 아래는 T2I-adapter를 이용해서 생성한 이미지들
Domain Adaptation via Prompt Learning
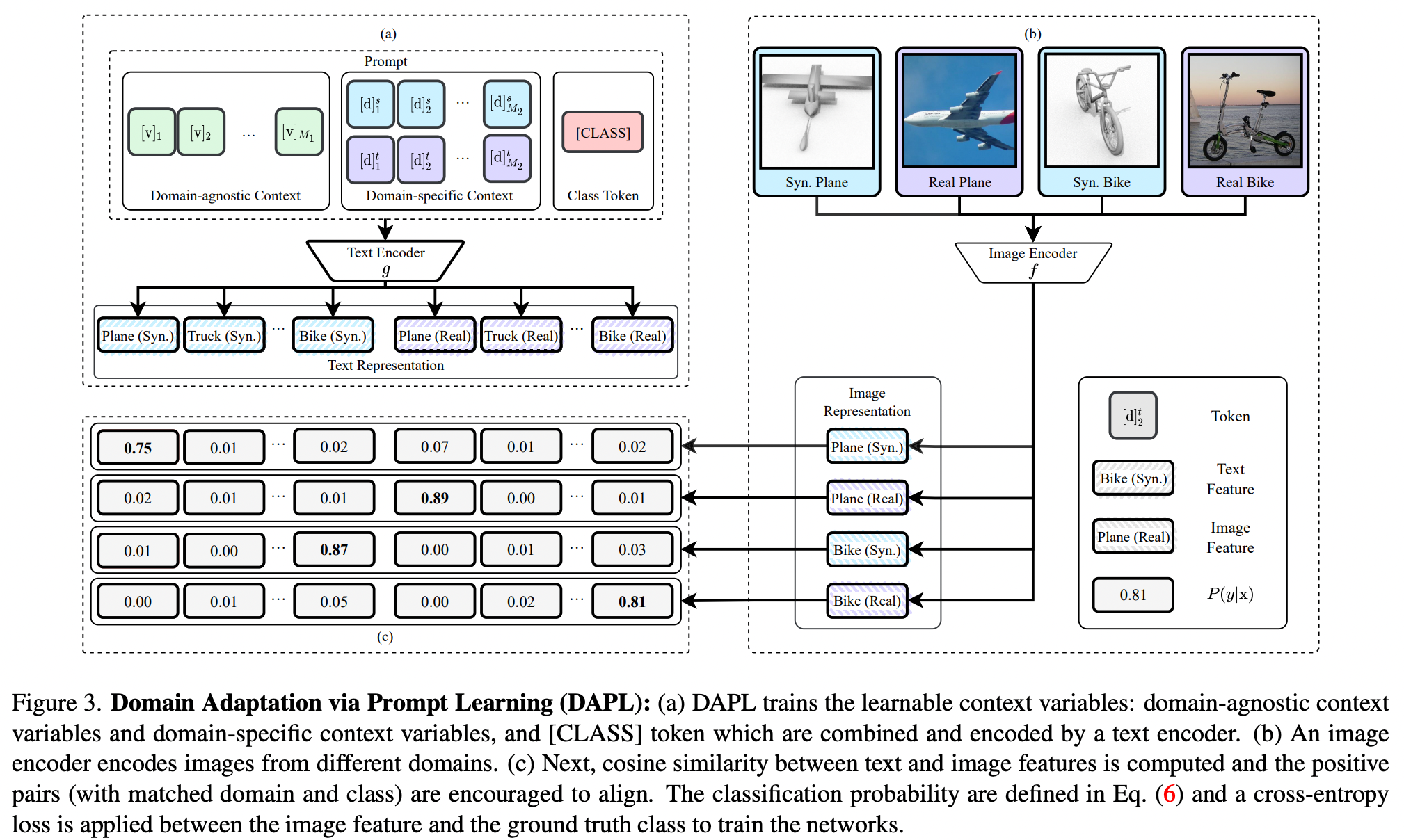
- prompt learning을 이용한 첫 Unsupervised Domain Adaptation 논문
- prompt + contrastive learning
- prompt를 만드는데, prompt는 Domain-agnostic, Domain-specific, Class label로 구성되어 있음 (위 그림의 (a) 혹은 아래 그림 참고)
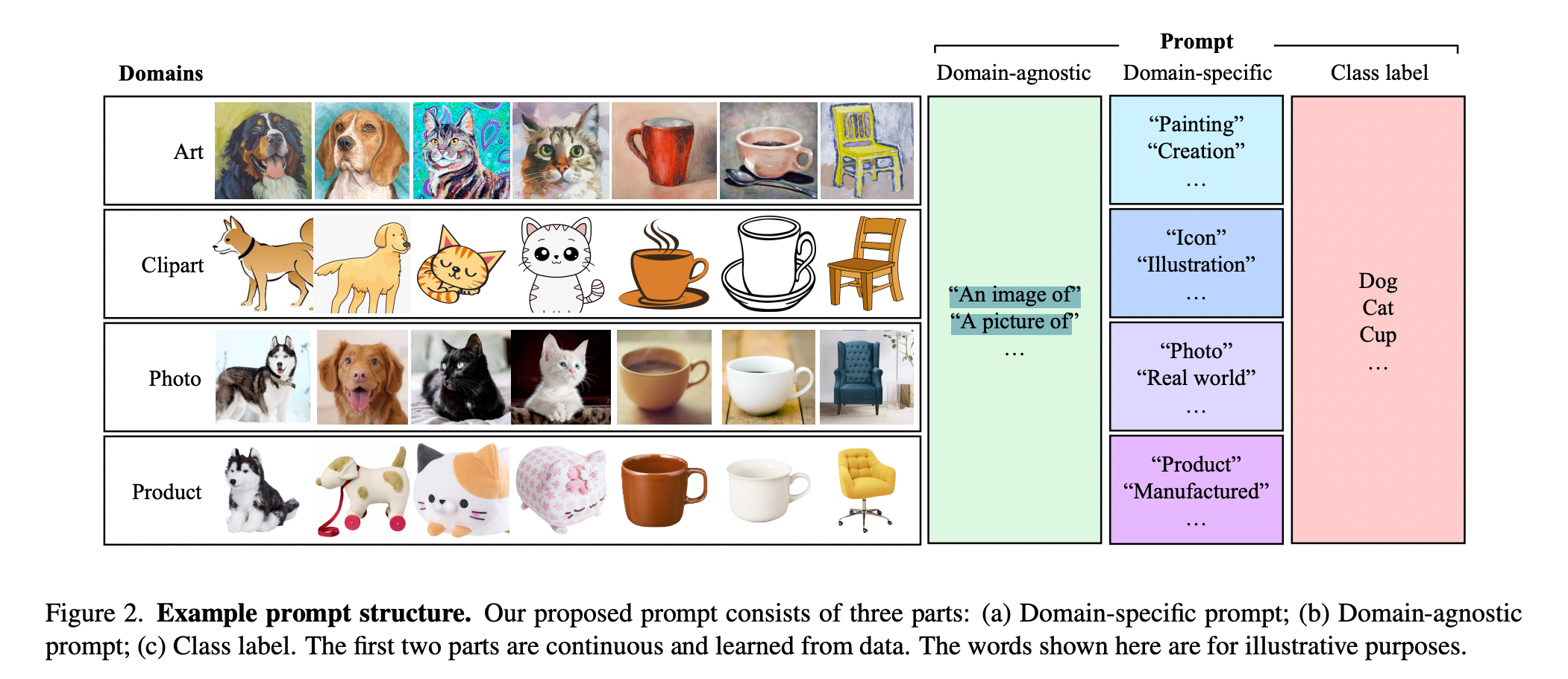
- CLIP을 백본으로 사용함
- training set에 대해서 학습할 때, image embedding과 text embedding의 cosine similarity가 해당 class에 속할 확률 (학습은 cross-entropy)
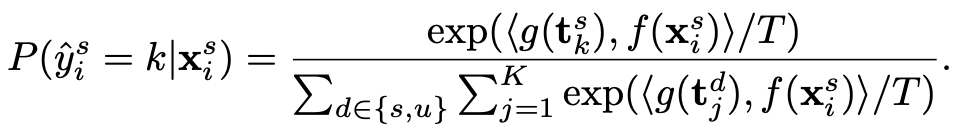
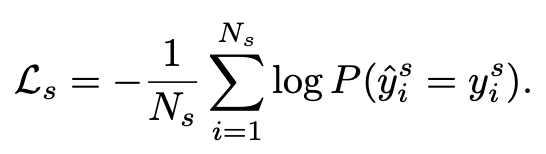
- target domain에 대해서 pseudo-label을 붙여주는데, 이는 예측한 확률이 가장 높은 class를 택함. (threshold를 넘었을 때만 선택)
- CLIP의 zero-shot 능력을 활용
- 아래 수식에서 I는 indicator function을 의미
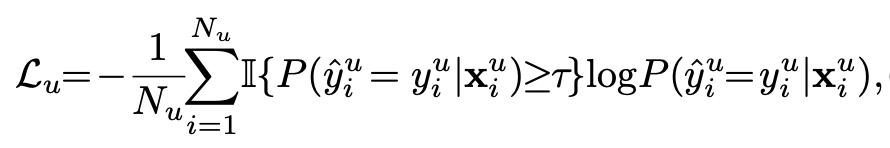
- 최종 로스는 Ls+Lu로 된다!
Continual Unsupervised Domain Adaptation in Data-Constrained Environments
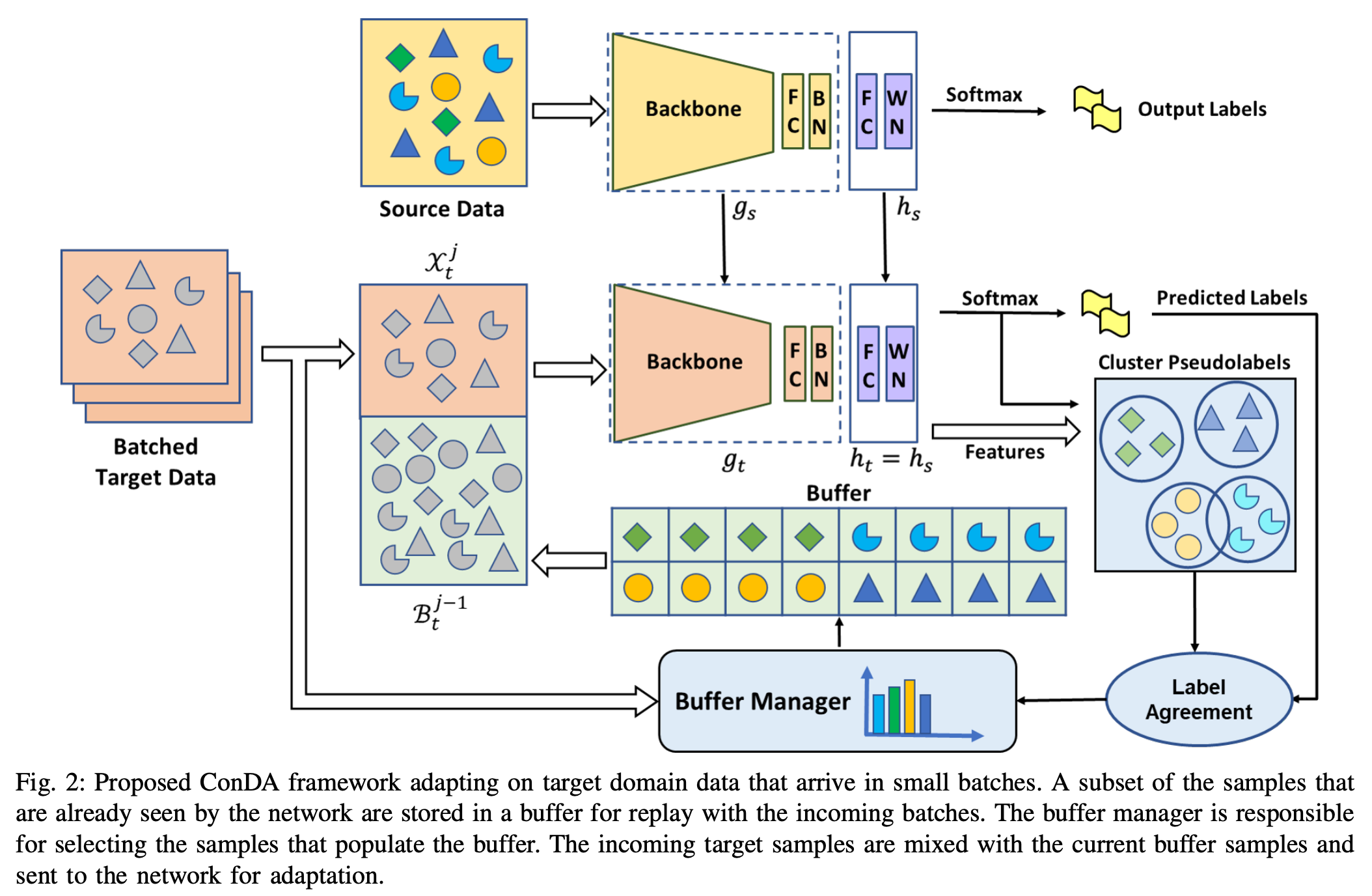
- Continual Domain Adaptation
- 백본만 학습, classifier는 고정
- Buffer를 어떻게 잘 다룰까에 초점 맞춘 듯
- 버퍼에 다 저장해두고,
- Buffer manage가 sample을 선택 (Predicted label과 pseudo label이 동일한 경우 선택)
- Pseudo label
- Cluster pseudo label은 softmax output과 feature 이용해서 cluster 중심을 정하고
- 각 feature에 pseudo label 할당
- K class인 애들의 cluster center를 다시 계산하고
- 최종 pseudo label 할당
- Cross-entropy loss + information maximization loss
[1] Wang, Yabin, Zhiwu Huang, and Xiaopeng Hong. "S-Prompts Learning with Pre-trained Transformers: An Occam's Razor for Domain Incremental Learning." arXiv preprint arXiv:2207.12819 (2022).
[2] Rostami, Mohammad. "Lifelong domain adaptation via consolidated internal distribution." Advances in neural information processing systems 34 (2021): 11172-11183.
[3] Mou, Chong, et al. "T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models." arXiv preprint arXiv:2302.08453 (2023).
[4] Ge, Chunjiang, et al. "Domain adaptation via prompt learning." arXiv preprint arXiv:2202.06687 (2022).