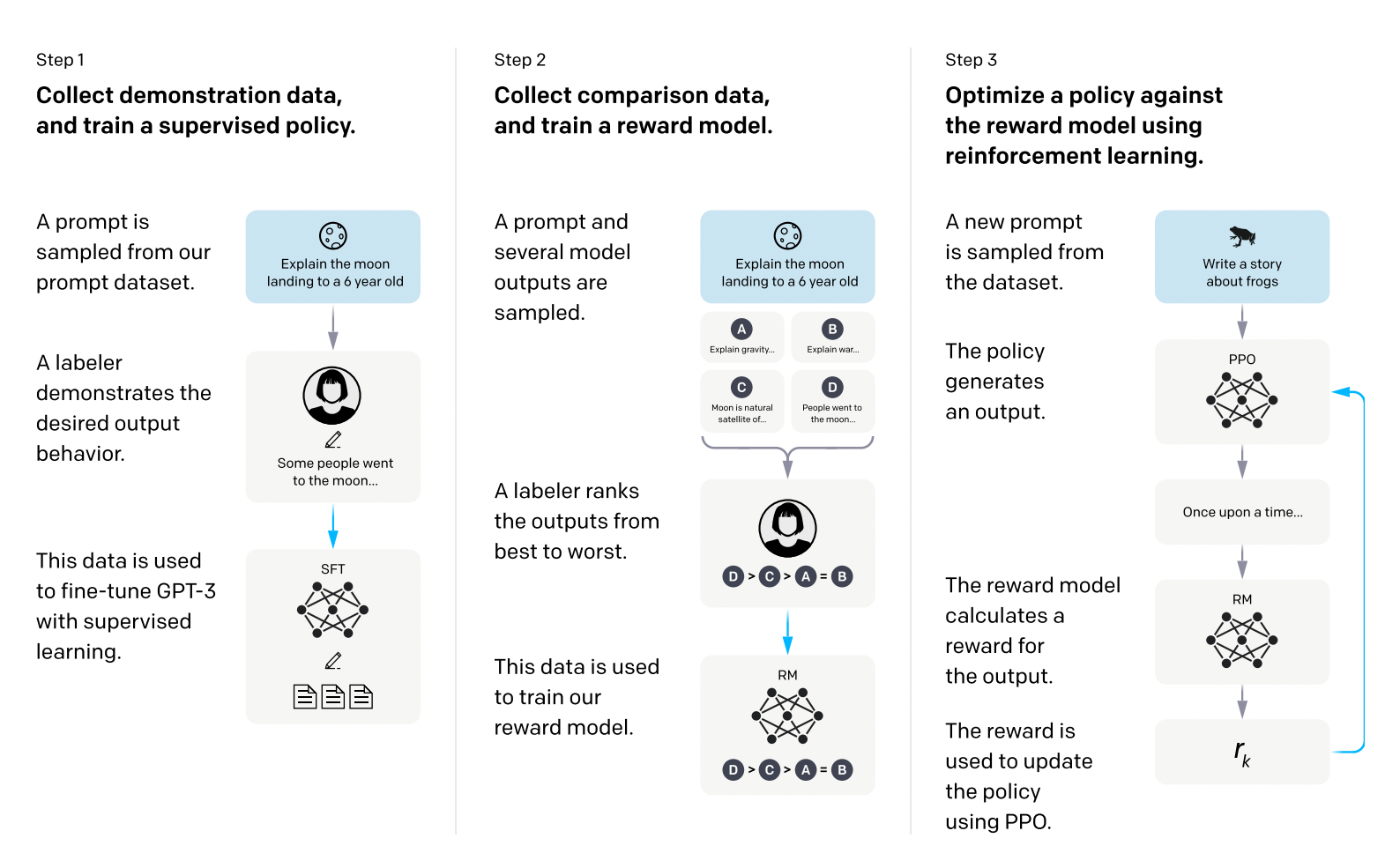
REINFORCEMENT Trust Region Policy Optimization (TRPO) policy gradient 기법에서 step-sizing이 매우 중요하다. 왜냐하면, supervised learning에서는 그 다음 update 할 때 어느정도 보완할 수 있지만, 강화학습에서는 step이 너무 커서 policy가 이상하게 변하면 그 이상한 policy 아래에서 다음 batch를 수집하게 된다. (계속 반복됨) 그래서 이를 해결하기 위해 등장한 것이 [yellow]TRPO[/yellow] 이다. TRPO는 policy update가 너무 많이 되지 않도록 KL divergence를 penalty로 준다. 위의 수식을 constraint 대신에 penalty항을 추가해서 풀게 되면 아래와 ..