오랜만에 읽은 논문ㅎㅎ.... 꾸준히 읽어야 하는데 논문 읽는 속도가 느리다보니 급한 일 생기면 그 일을 해결하느라 논문을 못 읽는 것 같다. 그래도 꾸준히 읽다보면 언젠간 논문 읽는 속도가 늘지 않을까....ㅎ...
컨셉
이번에 읽은 논문은 SagNet이라는 모델을 제시한 논문으로 AdaIN을 잘 활용한 논문이다. CNN에는 style에 대해 강한 bias가 존재하기 때문에 Domain Shift에 취약한데 content와 style을 분리해서 Domain Generalization 능력을 올리는 논문이다. content module과 style module을 두고, content와 style을 각각 학습하도록 하는 느낌
Style-Agnostic Networks
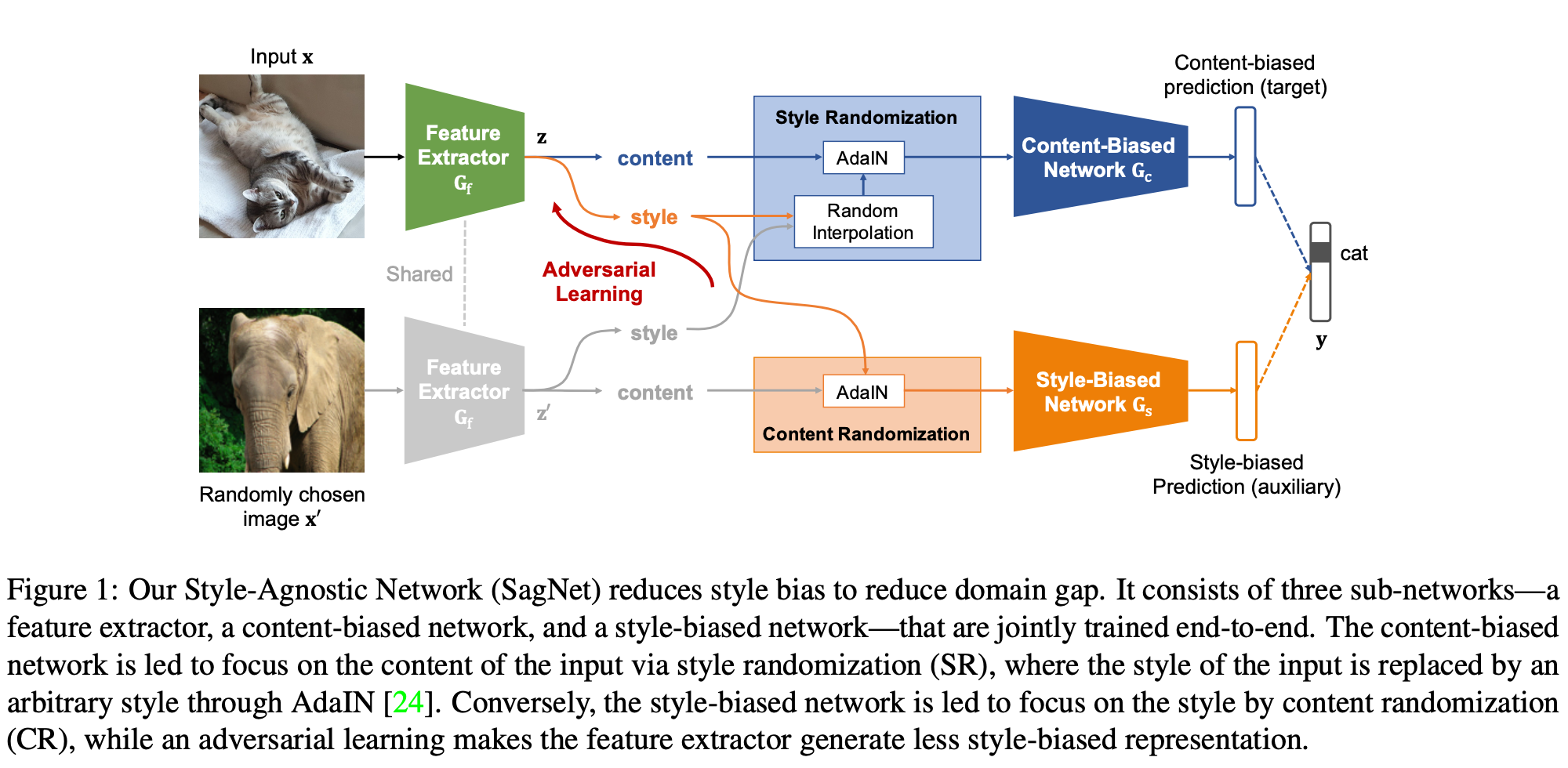
모델의 구조는 위와 같이 구성되어 있다. 3개의 network를 포함하고 있는데 feature extractor, content-biased network, style-biased network가 존재한다. Content-biased network는 이미지의 컨텐츠를 학습하고 반대로 style-biased network는 스타일을 학습한다.
Content-Biased Learning
style randomization module (SR) 모듈을 이용해서 content-biased feature를 학습한다. 학습 과정 동안 input image의 intermediate feature와 랜덤한 이미지의 intermediate feature를 interpolating해서 style을 randomaize한다. 수식을 보면 더 쉽게 이해할 수 있다.

input image의 intermediate feature를 $z$, 다른 랜덤한 이미지의 intermediate feature를 $z^{\prime}$라고 하면, 각각의 평균과 표준편차는 style representation이라고 볼 수 있다. (이는 AdaIN 논문 내용)

위의 수식을 통해서 input image의 컨텐츠와 input image와 랜덤한 이미지 사이의 interpolated style을 합치게 된다. 즉, [yellow]SR은 input image의 content와 input image와 랜덤한 이미지의 style을 섞어주는 모듈[/yellow]이라고 볼 수 있다.
위의 과정을 통해서 새로운 feature를 만들어 주고, 그 feature를 이용해서 classification을 해준다. 이 때, cross-entropy loss를 최소화하도록 학습되며, test 할 때는, SR 모듈을 통과하지 않는다. 아래 수식에서 $\mathbf{G}_c$는 content-biased network이고 (classification 역할도 한다고 이해함), $\mathbf{G}_f$는 feature extractor이다.

Adversarial Style-Biased Learning
Feature extractor $\mathbf{G}_f$가 Style-biased network $\mathbf{G}_s$를 속이도록 학습한다. Content-Biased Learning과 반대로 여기에서는 content randomaization (CR) 모듈이 존재한다. SR과 반대로 [yellow]CR는 input image의 style과 랜덤한 이미지의 content 정보를 합쳐주는 역할[/yellow]을 한다.


Content-Biased Learning과 마찬가지로, 여기서도 cross-entropy loss를 최소화하도록 학습된다. 또한, 아래와 같이 uniform distribution과의 cross-entropy loss도 최소화해주는데 이는 entropy를 최대화하는 것이라고 해석해도 된다고 한다. (그래서 모든 후보에 대해 균일하게 예측하도록 한다고 이해함)

Extension to Un/Semi-Supervised Learning
이 논문에서 언급한 또 다른 장점은 domain label이나 multiple domain이 필요없다는 점이었다. 이를 UDA, SSDA로 확장할 때 unlabeled data를 최대한 활용하기 위해서 consistency learning에 기반하여 확장한다고 한다. 예를 들어, unlabeld data인 $x$에 대해서, SR을 적용해서 prediction vector를 구하고 SR을 적용하지 않은 prediction vector를 구해서 그 둘이 일치하도록 한다고 한다. (아래 수식 참고) - 근데 이 둘 중 하나를 ground truth label 처럼 이용한다는 것인지, 두 개를 모두 이용한다는 것인지는 인용한 consistency learning을 봐야할 듯ㅎㅎ..
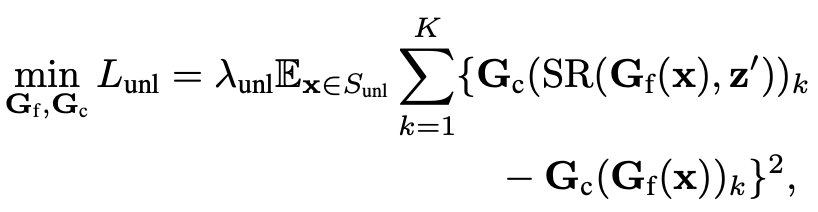
Experiments

성능이나 기타 분석은 본 논문을 읽어보는 것이 더 좋을 듯 하다. 위의 사진이 되게 재미있어 보여서 이것만 가져왔는데 위에 있는 단어가 content를 가져온 label이고 texture를 가져온 label이 아래에 적혀 있는 단어! content는 확실히 보이는데 style도 은은하게 보여서 신기했음ㅎㅎ
[1] Nam, Hyeonseob, et al. "Reducing domain gap by reducing style bias." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021.
[2] Github: https://github.com/hyseob/sagnet