📑 논문
논문 | 2023년 7월~8월 읽은 논문 정리
노바깅
2023. 9. 1. 16:34
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation

- 적은 양의 이미지 (5장-6장) 를 가지고 모델을 파인튜닝해서 개인을 위한 Text-to-Image Diffusion Model을 만들 수 있다!
- 'sks'와 같은 vocab에 없을 것 같은 특이한 단어 (identifier)를 객체 앞에 넣어서 같이 학습한다. (위의 사진에서 "A [V] dog" 부분의 [V]가 결국 identifier 같은 느낌
- Prior도 학습해서 원래 개의 특성도 학습하면서 [V] dog 이라는 특정 개만의 특성도 학습
FABRIC: Personalizing Diffusion Models with Iterative Feedback

- training free 방식으로, feedback image를 diffusion process에 조건으로 줌
- Attention-based Reference Image Conditioning: reference image를 key, value로 활용해서 추가적인 정보를 inject
- 처음에는 feedback image 없이 일단 이미지를 생성하고, 그 이미지로부터 "liked images"와 "disliked images"를 feedback으로 추가 (이미지 생성, 피드백, 새로운 이미지 생성 반복)
- Gradio: https://huggingface.co/spaces/dvruette/fabric
MAGVLT: Masked Generative Vision-and-Language Transformer

- image와 text를 모두 생성할 수 있는 masked generative VL transformer
- 여러 task에 대해 학습했기 때문에 robust
- 이미지 토큰과 텍스트 토큰 일부를 마스킹하고
- (이미지-마스킹된 텍스트)를 가지고 원래 텍스트를 예측하도록,
- (마스킹된 이미지-텍스트)를 가지고 원래 이미지를 예측하도록,
- (마스킹된 이미지-마스킹된 텍스트)를 가지고 원래 텍스트 혹은 이미지를 예측하도록 학습
- Step-Unrolled Mask Prediction 이라는 것도 제시했는데, 일단 한 번 예측한 후에 예측한 결과를 새로 마스킹하고 다시 예측하도록 함
- Inference 할 때는 iterative decoding을 통해 예측

- MixSel 이란 것도 제시했는데, (이미지-마스킹된 텍스트)가 input으로 주어질 때 서로 다른 2개의 이미지를 붙여서 주거나 (마스킹된 이미지-텍스트)가 input으로 주어질 때 서로 다른 2개의 텍스트를 붙여서 주거나 등 2개의 서로 다른 input이 주어지는데 이와 동시에 special token (<right>, <left>, <top>, <bottom>)이 주어짐. 이를 통해 bias 방지
On the Generalization of Multi-modal Contrastive Learning
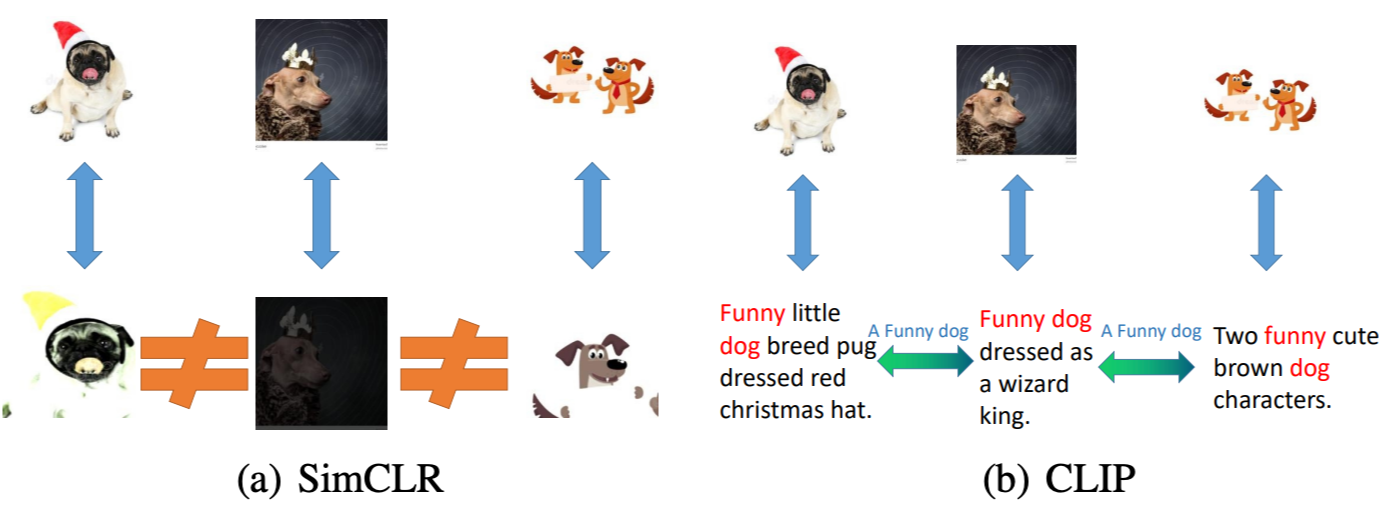
- Self-supervised learning(SSL)과 Multi-modal contrastive learning(MMCL)이 동일
- MMCL에서 텍스트 데이터를 활용하는 것은 SSL에서 데이터를 augmentation 하는 것과 동일하게 볼 수 있음.
- augmentation은 이미지 안에서만 연결성을 정의하지만, 텍스트 데이터를 활용하면 텍스트 도메인과 이미지 도메인 사이의 연결성도 정의하며, 암시적으로 의미적으로 비슷한 이미지들을 모아주는 역할을 함.
- CLIP을 이용해서 SimCLR 성능을 올리는 실험도 함.
Dynamic Graph Neural Networks Under Spatio-Temporal Distribution Shift

- spatio-temporal graph에서 distribution shift를 처리하기 위한 방법을 제시
- $y_t = f(P_I^t(v)) + \epsilon$, $P_I^t = \mathcal{G}_v^{1:t} \backslash P_V^t(v)$인 variant pattern $P_V^t(v)$과 invariant pattern $P_I^t(v)$이 존재한다는 가정하에, 모델이 더 좋은 generalization 능력을 갖기 위해서는 variant pattern 보다 invariant pattern에 따라 결정을 내려야 한다고 주장
- Disentangled Dynamic Graph Attention Networks
- scaled-dot product attention을 이용해서 variant mask와 invariant mask를 만들고 (이 때 두 개의 mask는 음의 correlation을 갖게 됨), 이웃 노드의 messages들을 잘 aggregation하고 각각 summarized variant pattern과 summarized invariant pattern으로 사용
- 이를 이용해서 hidden embedding 업데이트
- Spatio-Temporal Intervention Mechanism
- 앞선 단계에서 이용한 variant pattern을 이용해서 augmentation 하는 느낌
- invariant pattern은 유지하고 variant pattern을 갈아끼는 느낌
- Optimization with Invariance Loss
- invariant pattern만을 이용한 loss와
- variant pattern을 같이 이용한 loss (이를 통해서 multiple intervened distributions 에서도 모델이 잘 동작하도록)
- 두 가지 loss의 weighted sum이 최종 loss
DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data

- 이미지와 이미지 사이에 유사도를 계산하는 다양한 방법들이 제시되고 있지만 너무 low-level 이거나 image-level임.
- pixel이나 patch 단위로 유사도를 계산하는 LPIPS, PSNR, SSIM 등
- DINO나 CLIP은 임베딩을 통해 image-to-image 거리를 측정할 수 있음
- 위에 사진에서 볼 수 있듯이, 사람이 reference와 유사하다고 느끼는 이미지와 기존 방법들을 이용해서 선택한 유사한 이미지가 다름
- 본 논문에서는 이미지 triplet과 새로운 데이터셋을 구축하고, 이를 통해 fine-tuning한 tuned metric을 제시함.
- 데이터 수집 과정
- Stable Diffusion을 통해서 이미지들을 생성 및 수집
- 2AFC: (A, reference, B) triplet을 보고 A, B 중 reference와 무엇이 더 유사하다고 느끼는지 평가하고, 비슷하게 평가되는 triplet만 유지
- JND: (2AFC 검증용), 유저는 2개의 이미지 pair가 번갈아 가면서 보는데, 첫 번째와 세 번째가 동일한지와 두 번째와 네 번째가 동일한지에 대해 응답함.
- 수집한 데이터로 기존 메소드들을 fine-tuning 하고 더 좋은 tuned-metric을 얻음.
- DINO, CLIP과 같이 embedding을 얻고 그 embedding을 기반으로 거리를 구할 수 있는 모델을 fine-tuning
- 위의 그림 기준으로 reference 이미지와 A 이미지 사이의 거리를 d0이라고 하고, reference 이미지와 B 이미지 사이의 거리를 d1라고 하고, triplet loss를 이용하여 fine-tuning (이 때 거리는, 1-cos similarity)
- fine-tuning을 위해 MLP 레이어를 달아서도 해보고, LoRA를 이용해서 일부 파라미터만 학습도 해봤는데 LoRA를 이용한 경우가 모두 더 좋았음
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
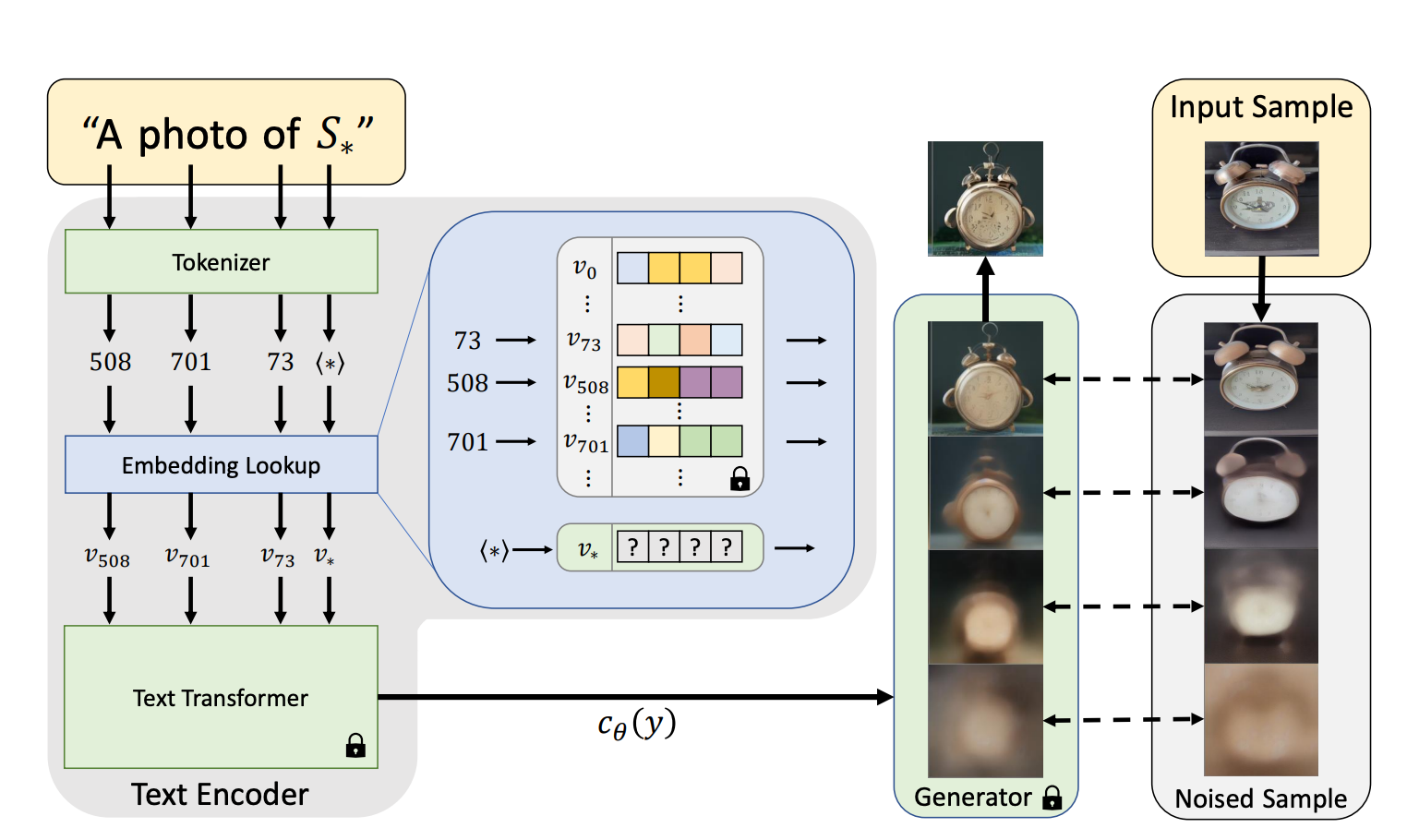
- Dreambooth와 같이 personalizing text-to-image generation task를 타겟팅한 논문
- 본 논문은 [yellow]Textual Inversion[/yellow]을 이용해서 $S_*$의 embedding vector를 학습하는데, 기존의 embedding들은 fix하고 해당 vector만 학습.
- $S_*$의 embedding vector를 학습하기 위한 loss는 아래와 같은데, 결국 Latent Diffusion Model loss와 동일하다. 다만, 이 때 denoising network인 $\epsilon_{\theta}$와 conditioning input을 conditioning vector로 바꿔주는 $c_{\theta}$는 fix
- 본 논문에서 $S_*$를 이용해서 reconstruct한 이미지와 다른 방식으로 reconstruct한 이미지를 비교하는데, $S_*$가 충분히 이미지의 detail을 잘 담고 있는 것을 알 수 있음
Concept Decomposition for Visual Exploration and Inspiration

- Visual concept을 분해
- 위의 그림에서 나무조각에 곰이 그려져있는 user 이미지를 보고, 그 이미지 안에 있는 sub concept들을 추론해서 binary tree를 만들어냄 (여기도 text inversion 활용)
- 한 번에 2개의 노드를 학습하는데, 각 노드는 각 sub concept에 해당하는 embedding vector라고 생각하면 됨
- parent node가 담고있는 concept을 묘사하는 이미지들을 생성 (root 노드는 parent 노드가 없으니 user가 입력으로 준 이미지를 사용)
- 기존 dictionary에 학습하고자 하는 2개의 벡터를 추가
- LDM loss를 통해서 학습하는데 이 때 prompt는 [yellow]"A photograph of $s_l$ $s_r$"[/yellow]
- 이렇게만 학습하면, concept이 모호하게 뽑히고, 전체적인 학습을 방해하는 경우가 생기기 때문에 이를 방지하기 위해서 sub concept을 묘사하는 벡터가 일관적인지 consistency test를 함. (벡터가 종종 일반적인 단어에서 벗어나는 경우가 있기 때문)
- k개의 seed에서 각 시드마다 sub concept vector pair를 만들고(위 그림에서는 $v_l, v_r$), 해당 벡터를 기반으로 이미지를 생성
- 그 후, 같은 컨셉이면 비슷하게 다른 컨셉이면 다른 이미지들이 생성되도록 하는 벡터 pair를 선택
[1] DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation, arxiv 2023
[2] FABRIC: Personalizing Diffusion Models with Iterative Feedback, arxiv 2023
[3] MAGVLT: Masked Generative Vision-and-Language Transformer, CVPR 2023
[4] On the Generalization of Multi-modal Contrastive Learning, ICML 2023
[5] Dynamic Graph Neural Networks Under Spatio-Temporal Distribution Shift, NeurIPS 2022
[6] DreamSim: Learning New Dimensions of Human Visual Similarity using Synthetic Data, arxiv 2023
[7] An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion, ICRL 2023
[8] Concept Decomposition for Visual Exploration and Inspiration, arxiv 2023